一、GATNE [2019]
《Representation Learning for Attributed Multiplex Heterogeneous Network》
network embedding或network representation learning是一种很有前途的方法,可以将网络中的节点投影到低维连续的空间,同时保持网络结构和固有属性。由于network embedding推动了节点分类、链接预测、社区检测等下游network learning的重大进展,因此它最近引起了人们的极大关注。DeepWalk, LINE, node2vec是将深度学习技术引入网络分析从而学习node embedding的开创性工作。NetMF对不同network embedding算法的等价性(equivalence) 进行了理论分析,而随后的NetSMF通过稀疏化给出了可扩展的解决方案。然而,它们被设计为仅处理具有单一类型节点和边的同质网络(homogeneous network) 。最近,人们针对异质网络提出了
PTE, metapath2vec, HERec。然而,现实世界的网络应用(例如,电商)要复杂得多,不仅包含多种类型的节点和边,还包含一组丰富的属性。由于embedding learning的重要性和挑战性,已有大量工作尝试来研究复杂网络的embedding learning。根据网络拓扑(同质的或异质的)、属性(带属性或不带属性),论文《Representation Learning for Attributed Multiplex Heterogeneous Network》对六种不同类型的网络进行了分类,并在下表中总结了它们的相对进展。这六个类别包括:同质网络(Homogeneous Network: HON)、属性同质网络(Attributed Homogeneous Network: AHON)、异质网络 (Heterogeneous Network: HEN)、属性异质网络 (Attributed Heterogeneous Network: AHEN)、多重异质网络 (Multiplex Heterogeneous Network: MHEN)、属性多重异质网络 (Attributed Multiplex Heterogeneous Network: AMHEN)。可以看到,人们对AMHEN的研究最少。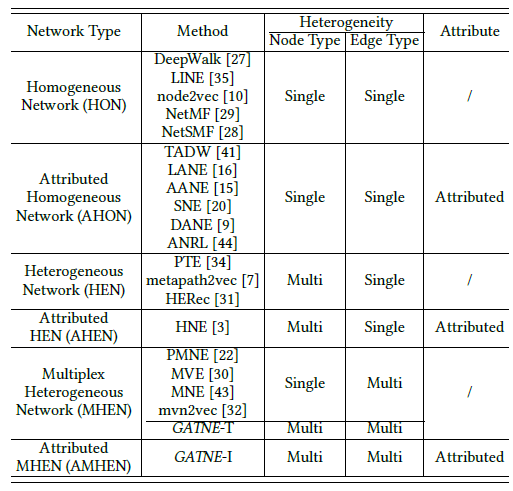
在论文
《Representation Learning for Attributed Multiplex Heterogeneous Network》中,作者专注于AMHEN的embedding learning,其中不同类型的节点可能与多种不同类型的边相连接,而且每个节点可能关联一组不同的属性。这在许多online application中很常见。例如,在论文使用的四个数据集中,Twitter有20.3%、YouTube有21.6%、Amazon有15.1%、Alibaba有16.3%的边具有不止一种类型。例如,在电商系统中,用户可能与item进行多种类型的交互,如点击(click)、转化(conversion) 、加购物车 (add-to-cart)、收藏 (add-to-preference)。下图说明了这样的一个例子。显然,user和item具有本质上不同的属性,不应该一视同仁。此外,不同类型的user-item交互意味着不同程度的兴趣,应该区别对待。否则,系统无法准确捕获用户的行为模式(behavioral pattern)和偏好,因此无法满足实际使用的需求。下图中,左侧的用户和属性相关联,用户属性包括性别、年龄、地域;右侧的
item也和属性相关联,item属性包括价格、品牌等。user-item之间的边有四种类型:点击、加购物车、收藏、转化(即购买)。中间的三个子图代表三种建模方式,从上到下依次为HON, MHEN, AMHEN。最右侧给出了在阿里巴巴数据集上不同模型相对于DeepWalk性能的提升。可以看到,GATNE-I相比DeepWalk提升了28.23%。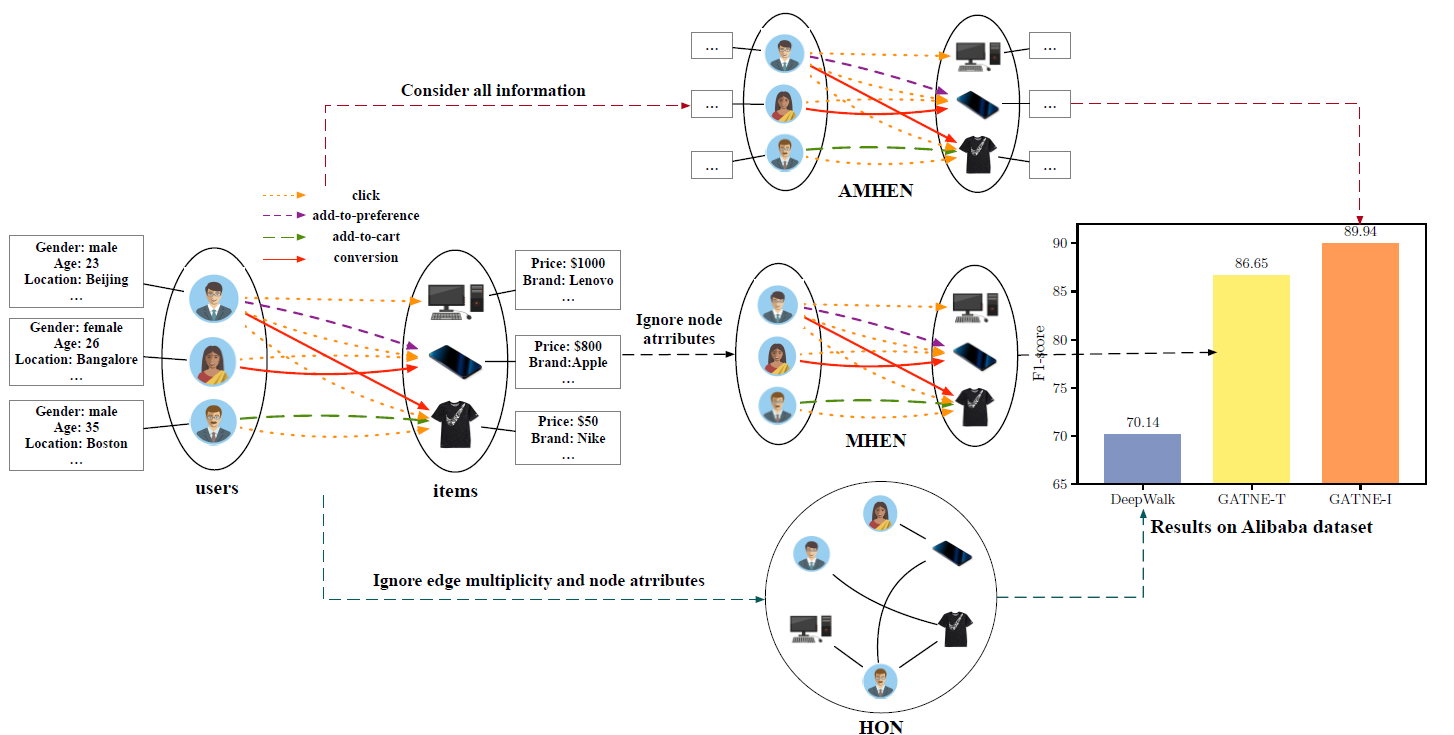
不仅因为异质性(
heterogeneity) 和多重性 (multiplicity),在实践中处理AMHEN带来了几个独有的挑战:多重边 (
multiplex edge):每对节点pair对之间可以存在多种不同类型的关系,因此结合不同类型关系并学习统一的embedding非常重要。部分观测 (
partial observation):真实网络的数据实际上只有部分被观测到。如,一个长尾用户可能只与某些商品产生很少的交互。现有的大部分network embedding方法仅关注于transductive场景,因此无法解决长尾或冷启动问题。可扩展性(
scalability):真实网络通常具有数十亿个节点、数百亿甚至千亿的边。因此模型的可扩展性非常重要。
为应对上述挑战,论文
《Representation Learning for Attributed Multiplex Heterogeneous Network》提出了一种新颖的方法来捕获丰富的属性信息,并利用来自不同节点类型的多重拓扑结构(multiplex topological structure),即通用属性多重异质网络嵌入 (General Attributed Multiplex HeTerogeneous Network Embedding: GATNE)。GATNE的主要特性如下:作者正式定义了
attributed multiplex heterogeneous network embedding问题,这是现实世界网络的更通用的representation。GATNE同时支持attributed multiplex heterogeneous network的transductive embedding learning和inductive embedding learning。论文还给出了理论分析,从而证明所提出的transductive模型比现有模型(如MNE更通用)。论文为
GATNE开发了高效且可扩展的学习算法,从而能够有效地处理数亿个节点和数十亿条边。
论文进行了广泛的实验,从而在四种不同类型的数据集(
Amazon, YouTube, Twitter, Alibaba)上评估所提出的模型。实验结果表明:与SOTA方法相比,论文的方法可以实现显著的提升。作者已经在阿里巴巴的分布式系统上部署了所提出的模型,并将该方法应用到了阿里巴巴的推荐引擎中。离线A/B test进一步证实了论文所提出方法的效果和效率。相关工作:这里我们回顾了
network embedding、heterogeneous network embedding、multiplex heterogeneous network embedding、attributed network embedding相关的SOTA方法。Network Embedding:network embedding方面的工作主要包括两类,graph embedding: GE、graph neural network: GNN。GE的代表工作包括:DeepWalk方法通过随机游走在图上生成语料库,然后在语料库上训练SkipGram模型。LINE学习大型网络上的node representation,同时保持一阶邻近性和二阶邻近性。node2vec设计了一个有偏的随机游走程序来有效地探索不同类型的邻域。NetMF是一个统一的矩阵分解框架,用于从理论上理解和改进DeepWalk, LINE。
GNN中的热门工作包括:GCN(《Semi-Supervised Classification with Graph Convolutional Networks》) 使用卷积运算将邻域的feature representation融合到当前节点的feature representation中。GraphSAGE提供了一种将网络结构信息和节点特征相结合的inductive方法。GraphSAGE学习representation函数而不是每个节点的直接embedding,这有助于它可以应用到训练期间unseen的节点。
Heterogeneous Network Embedding:异质网络包含各种类型的节点和/或边。众所周知,由于异质内容和结构的各种组合,这类网络很难挖掘。目前人们在嵌入动态的、异质的大型网络方面所作的努力有限。HNE共同考虑网络中的内容和拓扑结构,将异质网络中的不同对象表示为统一的向量representation。PTE从label信息和不同级别的word co-occurrence信息中构建大型异质文本网络,然后将其嵌入到低维空间中。metapath2vec通过metapath-based随机游走来构建节点的异质邻域,然后利用异质SkipGram模型来执行node embedding。HERec使用metapath-based随机游走策略来生成有意义的节点序列从而学习network embedding。这些embedding首先通过一组融合函数进行变换,然后集成到扩展的矩阵分解模型中。
Multiplex Heterogeneous Network Embedding:现有方法通常研究节点之间具有单一类型邻近关系(proximity) 的网络,它仅捕获网络的单个视图。然而,在现实世界中,节点之间通常存在多种类型的临近关系,产生具有多个视图的网络。PMNE提出了三种将多重网络投影到连续向量空间的方法。MVE使用注意力机制将多视图网络嵌入到单个协同的embedding中。MNE对每个节点使用一个common embedding以及若干个additional embedding,其中每种类型的边对应一个additional embedding。这些embedding由一个统一的network embedding模型来共同学习。mvn2vec探索了通过同时建模preservation和collaboration以分别表示不同视图中边语义(edge semantic meaning)从而实现更好的embedding结果的可行性。
Attributed Network Embedding:属性网络旨在为网络中的节点寻找低维向量representation,以便在representation中同时保持原始网络拓扑结构和节点属性邻近性。TADW在矩阵分解框架下,将节点的文本特征融入network representation learning中。LANE将label信息平滑地融合到属性网络embedding中,同时保持节点的相关性。AANE能够以分布式方式完成联合学习过程,从而加速属性网络embedding。SNE提出了一个通用框架,通过捕获结构邻近性和属性邻近性来嵌入社交网络。DANE可以捕获高度非线性并保持拓扑结构和节点属性中的各种邻近性。ANRL使用邻域增强自编码器对节点属性信息进行建模,并使用基于属性编码器和属性感知SkipGram模型来捕获网络结构。
1.1 模型
1.1.1 基本概念
给定图
异质网络(
Heterogeneous Network) 定义:一个异质网络heterogeneous) ,否则是同质的(homogeneous)。对于异质网络,考虑到节点
属性网络(
Attributed Network) 定义:一个属性网络属性多重异质网络(
Attributed Multiplex Heterogeneous Network: AMHEN)定义:一个属性多重异质网络AMHEN Embedding问题:给定一个AMHEN网络embedding。即,对每种边类型对节点
embedding,而不是所有视图共享一个embedding。这有两个好处:首先,可以通过各个视图的
embedding来聚合得到一个所有视图共享的embedding。其次,各个视图的
embedding保持了各个视图的语义,因此可以用于view-level的任务,例如某个视图下的链接预测。
我们首先在
transductive上下文中提出GATNE框架,对应的模型称作GATNE-T。我们还将GATNE-T与新的流行模型(如MNE)之间的联系进行了讨论。为解决部分观测(
partial observation) 问题,我们进一步将模型扩展到inductive上下文中,并提出了GATNE-I模型。针对这两个模型,我们还提出了有效的优化算法。
1.1.2 GATNE-T
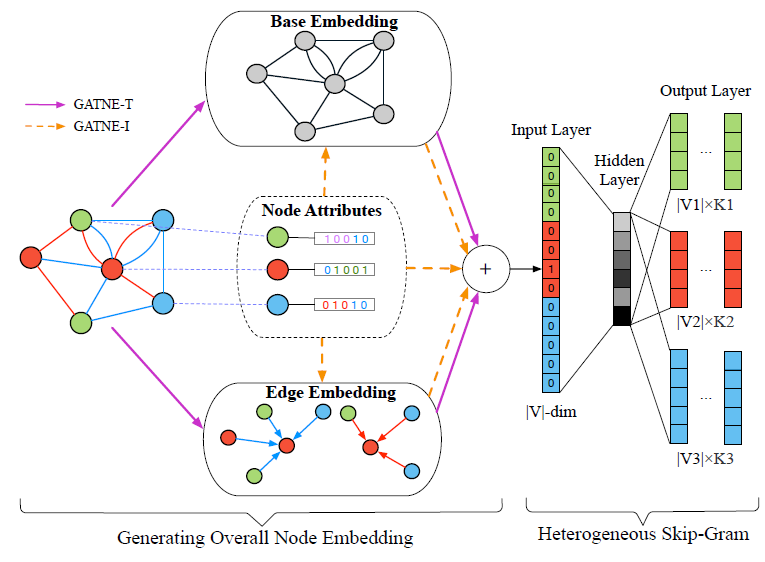
在
transductive环境中,我们将给定节点overall embedding拆分为两个部分,如下图所示:base embedding:节点base embedding在节点的不同边类型之间共享。edge embedding:节点embedding。
现在考虑
edge embedding。类似于GraphSage,我们假设节点embedding一共有embedding为:其中:
agg为一个聚合函数。类似于GraphSAGE,它可以为均值聚合:也可以为池化聚合,如最大池化:
其中
transductive模型中通过随机初始化。
第
K层embeddingembeddingembedding得到节点embedding矩阵:其中
edge embedding的维度,进一步地,我们使用
self-attention机制来计算加权系数edge embedding:其中:
edge embedding。
注意,这里在每种节点类型上都计算一个
self-attention,而并不是所有节点类型共享同一个self-attention。假设节点
base embedding为embedding为overall embedding为:其中:
edge embedding映射到和base embedding的同一空间。base embedding和edge embedding的重要性。令
另外,这里
embedding训练的目标是什么?要保持什么属性?论文都未提及。根据论文的示意图,猜测是用异质SoftMax保持一阶邻近性。
1.1.2 GATNE vs MNE
这里我们讨论
GATNE-T和MNE的关系。在GATNE-T中,我们使用attention机制来捕获不同边类型之间的影响因子。我们从理论上证明,GATNE-T是MNE的更为泛化的形式,可以提高模型的表达能力。在
MNE模型中,节点overall embedding为:其中
相比之下,
GATNE-T中,节点overall embedding为:其中
定理:对于任意
证明见原始论文。
因此,
GATNE-T的模型空间几乎包含了MNE的模型空间。
1.1.3 GATNE-I
GATNE-T的局限性在于它无法处理未观测数据。实际很多应用中,我们获得的数据只是部分观测的。这里我们将模型扩展到inductive环境中,并提出了GATNE-I。我们将节点
base embedding其中
即,不同类型的节点采用不同类型的映射函数。
注意:不同类型的节点可能具有不同维度的属性
类似地,节点
edge embedding其中
edge embedding,其中进一步地,在
inductive环境下,我们为最终的overall embedding添加了一个额外的属性项:其中
GATNE-T仅使用网络结构信息,而GATNE-I考虑了网络结构信息和节点属性信息。我们采用异质SkipGram算法,它的输出层给出了一组多项式分布,每个分布对应于输入节点如下图所示,这里有三种类型的节点(红色、绿色、蓝色)、两种类型的边(蓝色、橙色)。节点集合
GATNE-T和GATNE-I的区别主要在于base embeddingedge embedding在
transductive的GATNE-T中,每个节点的base embeddingedge embeddingGATNE-T无法处理训练期间未曾见过的节点。在
inductive的GATNE-I中,每个节点的base embeddingedge embeddingbase embeddingedge embedding
1.1.4 模型学习
下面我们讨论如何学习
GATNE-T和GATNE-I。我们使用随机游走来生成节点序列,然后使用SkipGram来学习节点embedding。由于输入网络的每个视图都是异质的,因此我们使用metapath-based随机游走。给定网络在边类型
metapath schemaschema的长度。则在随机游走的第其中
基于
metapath的随机游走策略可以确保不同类型节点之间的语义关系能够适当地融合到SkipGram模型中。假设随机游走在视图
给定节点
其中
和
metapath2vec一样,我们也使用heterogeneous softmax函数,该函数针对节点其中
context embedding向量,overall embedding向量。这里分母仅考虑节点
metapath给出。最后,我们使用异质负采样(
heterogeneous negative sampling)来近似每对其中:
sigmoid函数,noise distribution) 。GATNE算法:输入:
网络
overall embedding维度edge embedding维度学习率
一组
metapath schema负采样系数
随机游走序列长度
上下文窗口大小
平衡系数
模型深度
输出:每个节点
overall embedding算法步骤:
初始化模型所有的参数
对于每个边类型
metapath schema生成随机游走序列对每个边类型
迭代直到收敛。迭代步骤为:
节点
pair对在每个边类型上迭代(即根据
GATNE-T) 或者GATNE-I) 计算采样
更新模型参数:
GATNE算法中,基于随机游走算法的时间复杂度为overall embedding维度,空间复杂度为
edge embedding维度。
1.2 实验
这里我们首先介绍四个评估数据集和
baseline算法的细节。我们聚焦于链接预测任务,从而对比我们的方法与其它SOTA方法。然后我们讨论参数敏感性、收敛性、可扩展性。最后我们在阿里巴巴推荐系统上报告了我们方法的离线A/B test结果。数据集:
Amazon Product Dataset:它是来自Amazon的商品评论和商品metadata的数据集。在我们的实验中,我们仅使用商品metadata,包含商品属性以及商品之间的共同浏览(co-viewing), 共同购买(co-purchasing)关系。商品属性包括:价格、销售排名、品牌、类目。数据集的节点类型集合为
category)。如果考虑所有商品则规模庞大,因此我们选择“电子”类目的商品进行试验。但是对很多baseline算法来讲,电子类目的商品数量仍然过于庞大,因此我们从整个图中提取了一个连通子图(connected subgraph)。YouTube Dataset:由15088个用户的各种互动行为组成的多重网络。一共包含5种互动类型,包括: 联系(contact),共享好友(shared friends),共享的订阅 (shared subscription), 共享的订阅者(shared subscriber),共享的收藏视频(shared favorite vieoes)。因此在该数据集中,Twitter Dataset:包含2012-07-01到2012-07-07之间与希格斯玻色子(Higgs boson) 的发现相关的推文。它由450000名Twitter用户之间的四种关系组成,包括:转发(re-tweet),回复(reply),提及(mention),好友/关注者 (friendship/follower) 。 因此在该数据集中,Alibaba Dataset:包含user和item两种类型的节点,并且user-item之间存在四种交互类型。交互包括:点击(click) 、添加到收藏(add-to-preference)、加到购物车 (add-to-cart) 、以及转化(conversion)(即购买)。因此,整个数据集太大无法在单台机器上评估不同方法的性能,因此我们在采样后的数据集上评估模型性能。 采样的阿里巴巴数据集称作
Alibaba-S。另外,我们也在阿里巴巴分布式云平台上对完全的数据集进行评估,完整的数据集称作Alibaba。
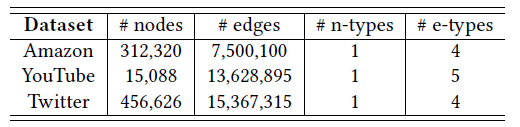
下表给出了这些数据集的统计信息,其中
n-types和e-types分别表示顶点类型和边类型的数量。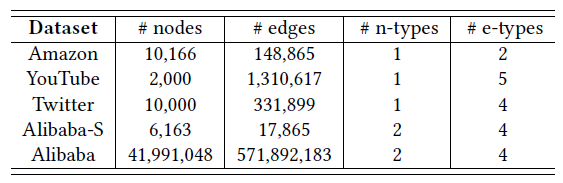
另外,由于单台机器的限制,我们用到的公共数据集是从原始公共数据集中采样的子图。下表给出了原始公共数据集的统计信息。
baseline:我们对比了以下几组baseline:Network Embedding Method:包括DeepWalk,LINE,noe2vec。由于这些方法只能处理同质图,因此我们向它们提供具有不同类型边的独立视图,并为每个视图获取node embedding。Heterogeneous Network Embedding Method:使用metapath2vec。当网络只有一种类型的节点时,它退化为DeepWalk。Multiplex Heterogeneous Network Embedding Method:比较的方法包括PMNE,MVE,MNE。我们将
PMNE的三种方法分别表示为PMNE(n),PMNE(r),PMNE(c)。MVE使用collaborated context embedding并将注意力机制应用于view-specific embedding。MNE对每种边类型使用一个comment embedding和一个additional embedding,这些embedding由统一的network embedding共同学习。Attributed Network Embedding Method:我们使用ANRL。ANRL使用邻域增强自编码器对节点属性信息进行建模,并使用基于属性编码器的属性感知SkipGram模型来捕获网络结构。Attributed Multiplex Heterogeneous Network Embedding Method:使用我们提出的GATNE。
另外,由于阿里巴巴数据集超过
4000万顶点、5亿条边,规模太大。考虑其它baseline的scalability,我们仅在该数据集上比较GATNE, DeepWalk, MVE, MNE等模型。对于一些没有节点属性的数据集,我们为它们生成节点特征。
运行环境:我们的运行环境分为两个部分:
一个是单台
Linux服务器,其配置为4 Xeon Platinum 8163 CPU @2.50GHz,512G Ram,8 NVIDIA Tesla V100-SXM2-16GB。该服务器用于训练四个较小的数据集。另一个是分布式云平台,包含数千个
worker,每两个worker共享一个NVIDIA Tesla P100 GPU(16GB显存) 。该平台用于训练最大的完整的阿里巴巴数据集。
单机版可以分为三个部分:随机游走、模型训练和模型评估。随机游走部分参考
DeepWalk和metapath2vec的相应部分来实现。模型训练部分参考tensorflow的word2vec教程来实现。模型评估部分使用了scikit-learn中的一些标准评估函数。模型参数通过使用Adam的随机梯度下降进行更新和优化。分布式版根据阿里巴巴分布式云平台的编程规范来实现,以最大化分布式效率。
参数配置:
所有方法的
base/overall embedding维度均为edge embedding维度为每个节点开始的随机游走序列数量为
10,随机游走序列长度为10,上下文窗口大小为5,负采样系数为5,用于训练SkipGram模型的迭代数量为100。对于阿里巴巴数据集,
metapath schema设置为U-I-U和I-U-I。其中U表示用户顶点,I表示item顶点。(metapath2vec和GATNE都采用这种schema)DeepWalk:对于小数据集(公开数据集和Alibaba-S数据集),我们使用原作者的Github代码。对于阿里巴巴数据集,我们在阿里云平台上重新实现了DeepWalk。LINE:我们使用原作者的Github代码。我们使用LINE(1st+2nd)作为overall embedding。一阶embedding和二阶embedding大小均为100。样本量设为10亿。node2vec:我们使用原作者的Github代码,其中超参数metapath2vec:作者提供的代码仅适用于特定的数据集,无法推广到其它数据集。我们基于原始C++代码,用python重新开发从而为任意顶点类型的网络重新实现了metapath2vec。对于三个公共数据集,由于节点类型只有一种,因此
metapath2vec退化为DeepWalk。对于阿里巴巴数据集,metapath schema设置为U-I-U和I-U-I。PMNE:我们使用原作者的Github代码,其中PMNE(c)的层级转移概率为0.5。MVE:我们通过email从原作者取到代码。每个视图的embedding维度为200,每个epoch训练样本为1亿,一共训练10个epoch。对于阿里巴巴数据集,我们在阿里云平台上重新实现了该方法。
MNE:我们使用原作者的Github代码。对于阿里巴巴数据集,我们在阿里云平台上重新实现了该方法。我们将
additional embedding维度设为10。ANRL:我们适用来自阿里巴巴的Github代码。由于
YouTube和Twitter数据集没有节点属性,因此我们为它们生成节点属性。具体而言,我们将顶点经过DeepWalk学到的200维embedding视为节点属性。对于
Alibba-S和Amazon数据集,我们使用原始特征作为属性。GATNE:最大的
epoch设为50。如果ROC-AUC指标在验证集上有1个训练epoch未能改善,则我们执行早停。对于每个边类型
1。我们使用
tensorflow的Adam优化器,并使用默认配置,学习率设为0.001。对于
A/B test试验,我们设置top N命中率)。GATNE可以采用不同的聚合函数,如均值聚合或池化聚合都达到了相似的性能。最终我们在这里使用了均值聚合。在
GATNE-I中,我们采用
我们通过链接预测任务来比较不同模型的效果。对于每个原始图,我们分别创建了一个验证集和测试集。
验证集包含
5%随机选择的postive边、5%随机选择的negative边,它用于超参数选择和早停。测试集包含
10%随机选择的postive边、10%随机选择的negative边,它用于评估模型,并且仅在调优好的超参数下运行一次。我们使用ROC曲线 (ROC-AUC)、PR曲线(PR-AUC)以及F1指标来评估。所有这些指标都在所选择的边类型之间取均值。
我们将剔除这些
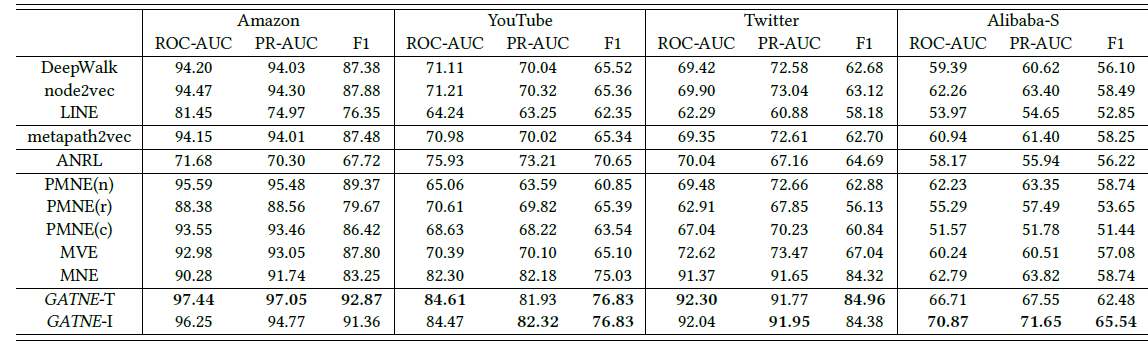
postive边剩下的图作为训练集来训练embedding以及分类器。下图给出了三个公共数据集和Alibba-S的试验结果。可以看到:
GATNE在所有数据集上优于各种baseline。由于节点属性比较少,所以
GATNE-T在Amazon数据集上性能优于GATNE-I。而阿里巴巴数据集的节点属性丰富,所以GATNE-I的性能最优。ANRL对于节点属性比较敏感,由于Amazon数据集的节点属性太少,因此其效果相对其它baseline最差。另外,阿里巴巴数据集中
User和Item的节点属性位于不同的空间,因此ANRL在Alibaba-S数据集上效果也很差。在
Youtube和Twitter数据集上,GATNE-I性能类似于GATNE-T,因为这两个数据集的节点属性是Deepwalk得到的顶点embedding,它是通过网络结构来生成的。
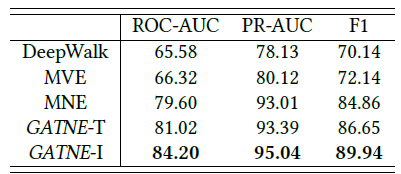
进一步地,我们给出阿里巴巴数据集的实验结果。
GATNE可以很好地扩展到阿里巴巴数据集上,并实现最佳效果。与之前的state-of-the-art算法相比,PR-AUC提高2.18%、ROC-AUC提高5.78%、F1得分提高5.99%。在大规模数据集中,
GATNE-I的性能超越了GATNE-T,这表明inductive方法在AMHEN中效果更好。
收敛性分析:我们在阿里巴巴数据集上分析了
GATNE的收敛性,如下图所示。可以看到:在大规模真实数据集上,GATNE-I的收敛速度更快、性能更好。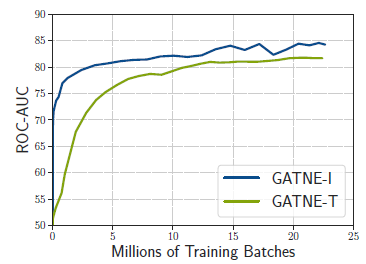
可扩展性分析:我们研究了
GATNE的scalability。如下图所示,我们给出了阿里巴巴数据集中,不同worker数量的加速比。可以看到:GATNE在分布式平台上具有很好的可扩展性,当增加worker数量时训练时间显著降低。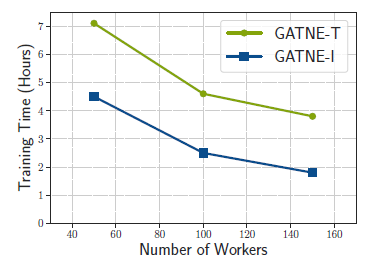
超参数敏感性:我们研究了不同超参数的敏感性,包括
overall embedding维度edge embedding维度GATNE的性能。可以看到:GATNE的性能在较大范围的d或s时相对稳定,当d或s太大或太小时性能会有降低。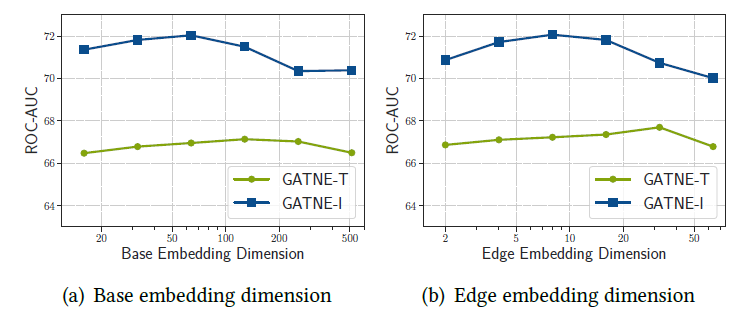
我们在阿里云分布式平台上为我们的推荐系统部署了
GATNE-I。训练数据集包含1亿用户和1000万item, 每天有100亿次交互。我们用该模型为用户和商品生成embedding向量。对于每个用户,我们使用kNN和欧式距离来计算用户最有可能点击的top N item。我们的目标是最大化top N的命中率。推荐的
topN列表中包含用户点击的商品,则认为是命中。命中的推荐列表占所有推荐列表的比例,则为命中率。在
A/B test框架下,我们对GATNE-I, MNE, DeepWalk进行离线测试。结果表明:与GATNE-I的命中率比MNE提高3.25%、比DeepWalk提高24.26%。这一对比没有多大实际意义,因为阿里巴巴在线推荐框架不太可能是
MNE或者DeepWalk这种简单的模型。目前已有的一些公共数据集,并没有公开的训练集、验证集、测试集拆分方式。这导致在同一个数据集上进行随机拆分,最终评估的结果会不同。因此,我们无法使用先前论文中的结果。研究人员必须重新实现并运行所有的
baseline模型,从而减少了他们对于改进自己提出的模型的关注。这里我们呼吁所有的研究人员提供标准化的数据集,其中包含标准化的训练集、验证集、测试集拆分。研究人员可以在标准环境下评估他们的方法,并直接比较各论文的结果。这也有助于提高研究的可重复性 (
reproducibility)。除了网络的异质性之外,网络的动态性对于网络表示学习也至关重要。捕获网络动态信息的方法有三种:
可以将动态信息添加到节点属性中。如我们可以用
LSTM之类的方法来捕获用户的动态行为。动态信息(如每次交互的时间戳)可以视为边的属性。
可以考虑代表网络动态演化的几个快照。
我们将动态属性的多重异质网络的
representation learning作为未来的工作。